2023 iThome 鐵人賽
分享至
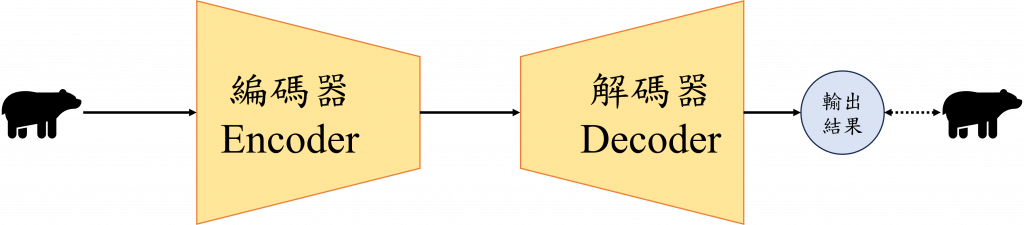
今天我們要來講一個新的東西:自編碼器,它用到的是「非監督式學習」的概念,這和之前我們討論的內容都不太一樣,所以內容上會分成兩天來介紹,讓大家更好的吸收!
IT邦幫忙


 iThome鐵人賽
iThome鐵人賽